Use reference documentation tools with AI agents
Stop babysitting the model with pasted snippets. Pull the right docs into context automatically.
The fastest way to lose trust in an AI coding workflow is to ask for something routine, get an answer that sounds right, then discover it's based on an older version of the library.
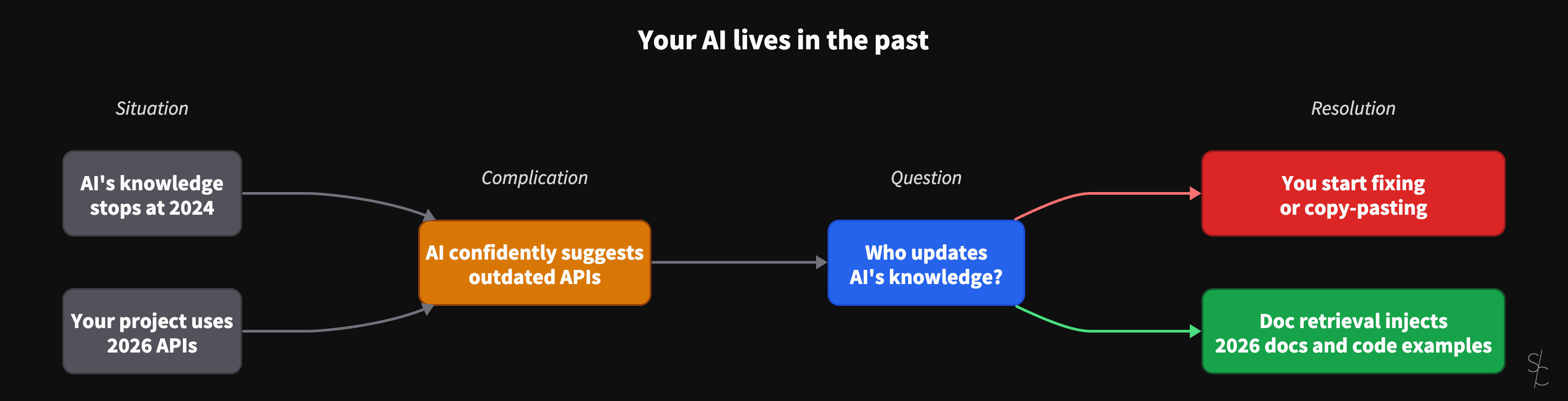
The failure mode is familiar. The imports look plausible. The API names are almost correct. The code compiles, or nearly compiles. You burn twenty minutes correcting details the model delivered with complete confidence.
This isn't a model "being dumb." It's a model doing exactly what it can do. Predict text. The problem is that training data has a cutoff, while your dependencies keep moving.
The gap between training cutoff and the version you run
When you prompt an agent to implement something with a modern framework, you're asking it to bridge two worlds. What it saw during training, and what your project is actually using today.
If those worlds drift, you get hallucinated APIs and outdated patterns. The fixes tend to look the same. You retry the prompt with more hints. You paste documentation snippets into context. You accept "close enough" and clean up the rest by hand.
None of this is hard work. It's just expensive work. The kind that quietly drains the point of having an agent in the first place.
The cure isn't a better pep talk in your prompt. The cure is reference documentation retrieval.
Dynamic documentation retrieval
Context7 is an MCP server that pulls version-specific documentation dynamically. Instead of pre-loading docs, you mention a library in your prompt, and it fetches the right material.
This matters when your day is a mix of ecosystems. One moment you're in Supabase auth, the next you're in a UI library, then you're back in an API client. Context7 is designed for that kind of switching. It handles over 1,000 public libraries automatically.
For private knowledge (internal policies, compliance docs, ADRs), Context7 supports private documentation with a paid plan. You can add your own libraries, private repos, and internal docs to the same retrieval system you use for public libraries.
GitHits takes a different approach. Instead of indexing documentation, it searches GitHub in real-time and distills code examples from public repositories. The MCP server is currently on a waitlist.
The payoff
Documentation retrieval doesn't improve reasoning. It improves what the model has to reason about.
When the right snippet of reference material is sitting in the context window, you get fewer hallucinated imports. Correct API signatures more often. Fewer back-and-forth retries. Working software instead of plausible-looking broken code.
Once you feel that shift, it's hard to go back. You stop babysitting the model with pasted snippets. You start treating retrieval as part of the toolchain, alongside linting, tests, and CI.
If you're building with agents today, start small. Add one reference source you trust. Run the same kind of prompt you normally run. Compare the output quality.
You'll notice the difference in the first hour.
More from the blog
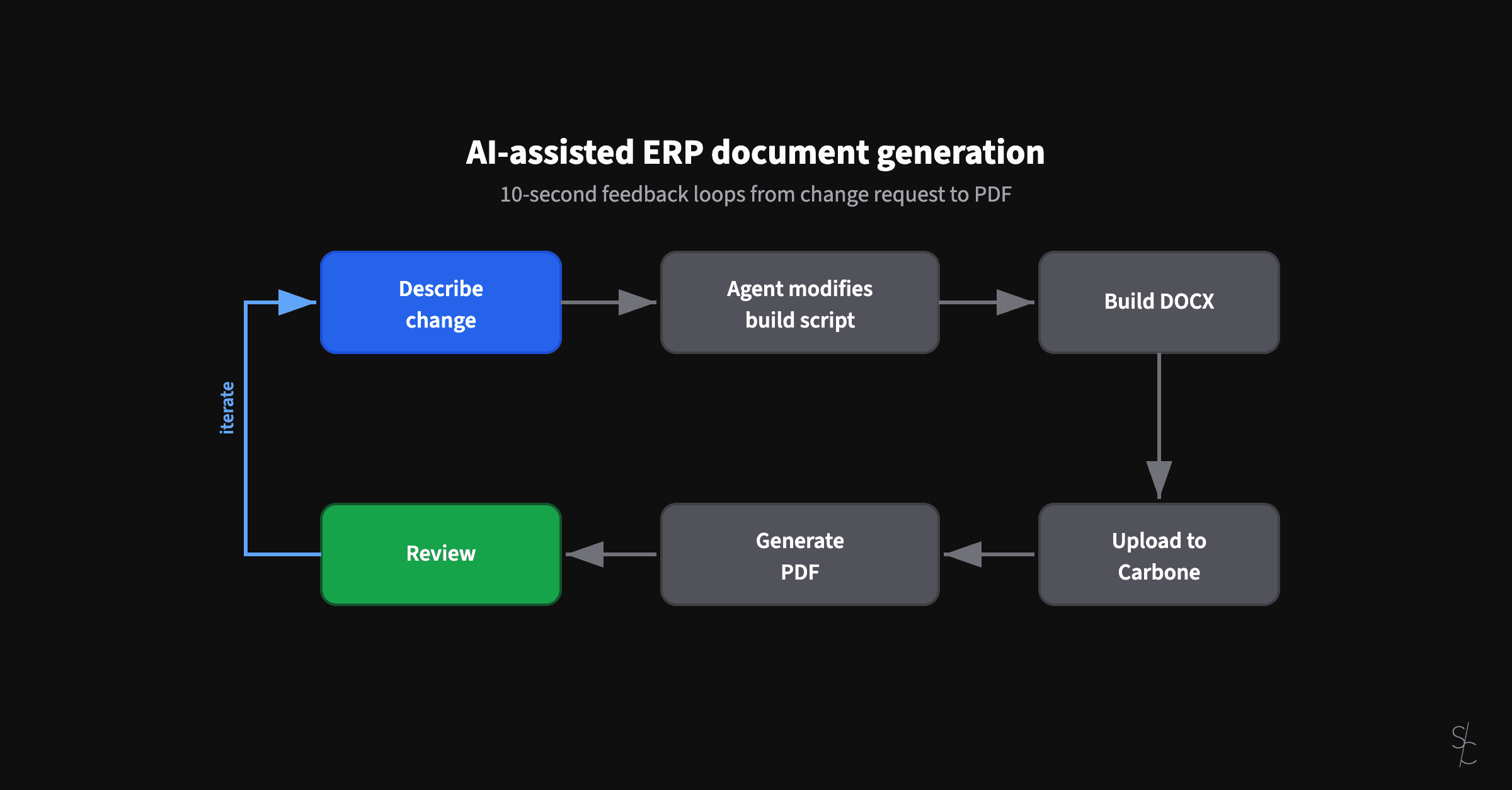
AI-assisted ERP document generation
ERP documents look simple. Underneath, they're conditional logic puzzles that have resisted modernization for decades.
Subagents replaced my /code-review command
Rules tell agents what to do. Subagents verify they actually did it.

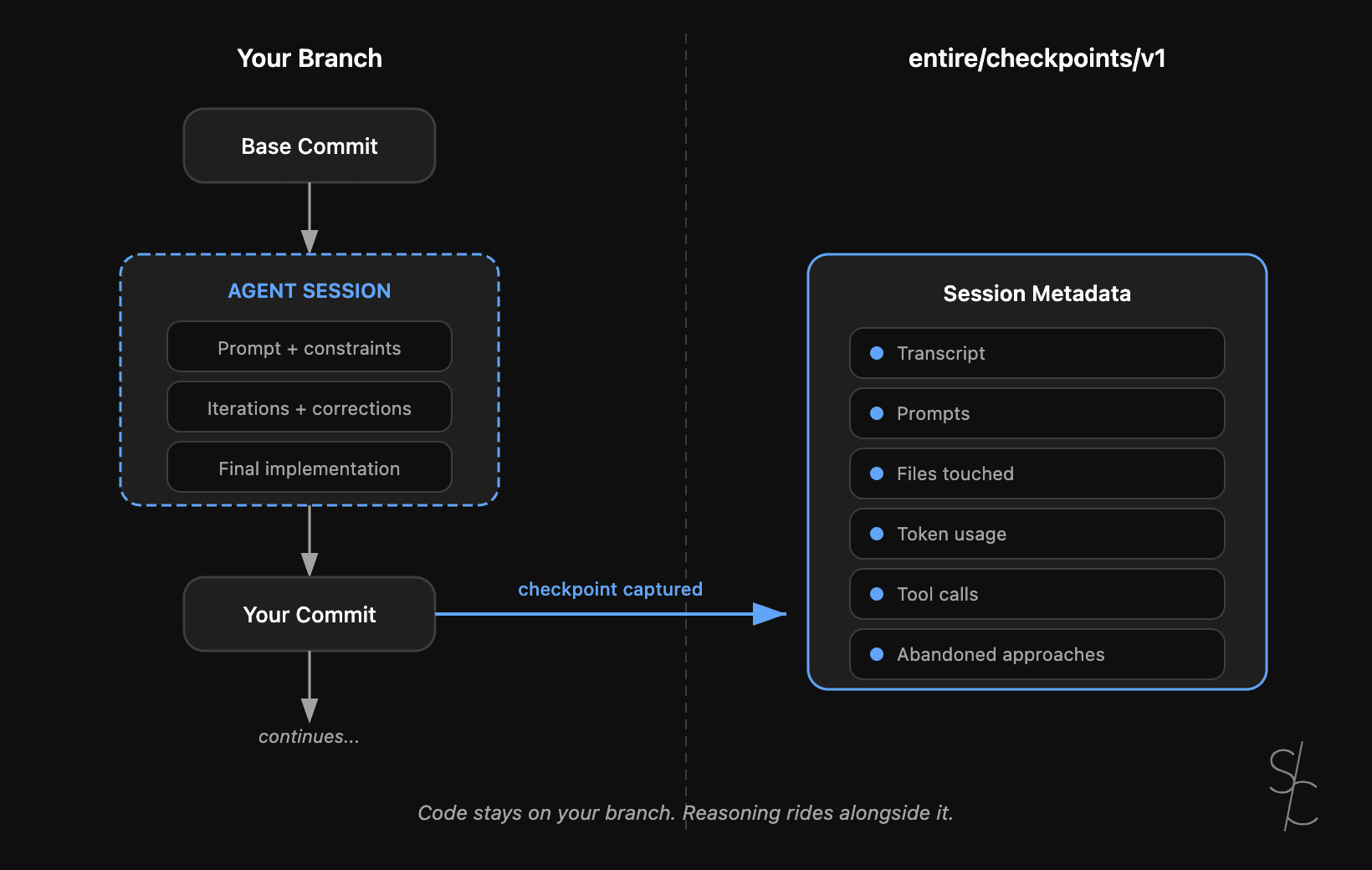
Agent context is the new technical debt
Git tracks what changed. With AI-generated code, the reasoning behind it matters more. Entire makes that context durable.