Subagents replaced my /code-review command
Rules tell agents what to do. Subagents verify they actually did it.
I used to end every big agent task with /code-review. A slash command that kicked off a manual review pass. The agent would re-read its own output, check for mistakes, and report back. It worked, but it was a leash I had to remember to pull. Forget to run it, and you ship whatever the agent produced on autopilot.
That workflow is gone now. Both Cursor and Claude Code support subagents, and I replaced /code-review with a code-reviewer subagent that runs itself automatically after every meaningful code change. No manual trigger. No forgetting.
The shift sounds small. It changed how I think about agent supervision entirely.
When context rots
I wrote about letting AI supervise itself earlier this year. The core idea: wire the agent into your development toolchain so mistakes get caught automatically. Linters, type checkers, tests, CI. The more the agent can access, the less you need to review by hand.
That workflow assumed the agent remembers what you told it. It often doesn't.
I keep rules and skills scattered across my project. In Cursor, rules (.cursor/rules/) define persistent coding standards that load automatically based on file patterns. Skills (.cursor/skills/) handle more complex multi-step workflows the agent can invoke. Claude Code has the equivalent: CLAUDE.md files for project instructions, .claude/rules/ for file-scoped rules, and .claude/skills/ for invocable workflows. Both tools also support AGENTS.md files at various levels of the directory tree. The guidance is there.
But when I crunch a large feature, the agent's context window fills up. Implementation details, terminal output, file contents. The useful space shrinks. At some point the agent starts dropping things. Not dramatically. It doesn't announce "I forgot your rules." It just quietly stops following them. An any type slips in. A server action skips the validation wrapper. RLS policies get written but not tested. The gap between what you told the agent and what it actually produced widens without warning.
Rules and skills are proactive. They tell the agent what to do before it starts working. But they can't verify the output after the context has degraded. That verification needs a fresh perspective.
What subagents solve
A subagent is a specialized AI assistant that runs in its own context window. The parent agent delegates a task, the subagent works independently with a clean context, and returns its result. Both Cursor and Claude Code support them natively now. You define them as markdown files in .cursor/agents/ or .claude/agents/ with YAML frontmatter and a system prompt.
Three properties make subagents different from rules or skills:
Context isolation. Each subagent starts fresh. It doesn't inherit the bloated context of the parent conversation. When my main agent has been implementing a feature for 30 minutes and its context is packed with file edits and terminal output, the reviewer subagent launches with a clean slate. It reads the code as-is, not as the parent agent remembers it.
Automatic delegation. The parent agent reads the subagent's description field and decides when to delegate. If the description says "use proactively after every task," the agent does exactly that. No /code-review command needed.
Specialized focus. The subagent's prompt is tuned for one job. It doesn't carry the cognitive load of the implementation task. It just reviews.
The code-reviewer
Here's the subagent that replaced my /code-review command. The full file is in the "Creating your own subagent" section below, but the key is the description field. Mine says "MUST USE after ending every task" and includes few-shot examples showing the parent agent concrete scenarios where delegation should happen: after creating a component, after adding an API route, after refactoring shared code. The parent agent reads these examples and learns the pattern. Without them, "use proactively" is vague. With them, the agent sees exactly what proactive means in practice.
The system prompt covers five review areas:
TypeScript standards. No any types. Implicit type inference preferred. Proper error handling. Service patterns for server-side APIs. No mixing client and server imports from the same file.
React and Next.js compliance. Functional components only. useEffect flagged as a code smell requiring justification. Single state objects preferred over stacking useState calls. Server Components for data fetching. Loading indicators on async operations. Forms with react-hook-form and proper validation wrappers.
Architecture validation. Multi-tenant patterns with account-based access control. Shared UI components over one-off packages. Proper import patterns for the monorepo structure.
Database security. RLS policies on every table. Column-level permissions. Triggers for timestamps and user tracking. Constraints that prevent invalid data at the schema level.
Code quality metrics. No unnecessary abstraction. Consistent file structure. Proper package organization.
The output is structured by severity: critical issues, high priority, medium priority, low priority, security assessment, positive observations, and a prioritized action items list. The parent agent reads this report and fixes what it finds.
The key design decision: this subagent doubles as architecture enforcement. When I make architectural changes to the project, I update the subagent prompt to match. If I add a new pattern for handling redirects after server actions, the reviewer now checks for it. If I decide all forms should use a specific validation wrapper, the reviewer flags forms that don't. The subagent becomes a living architectural checklist that evolves with the codebase.
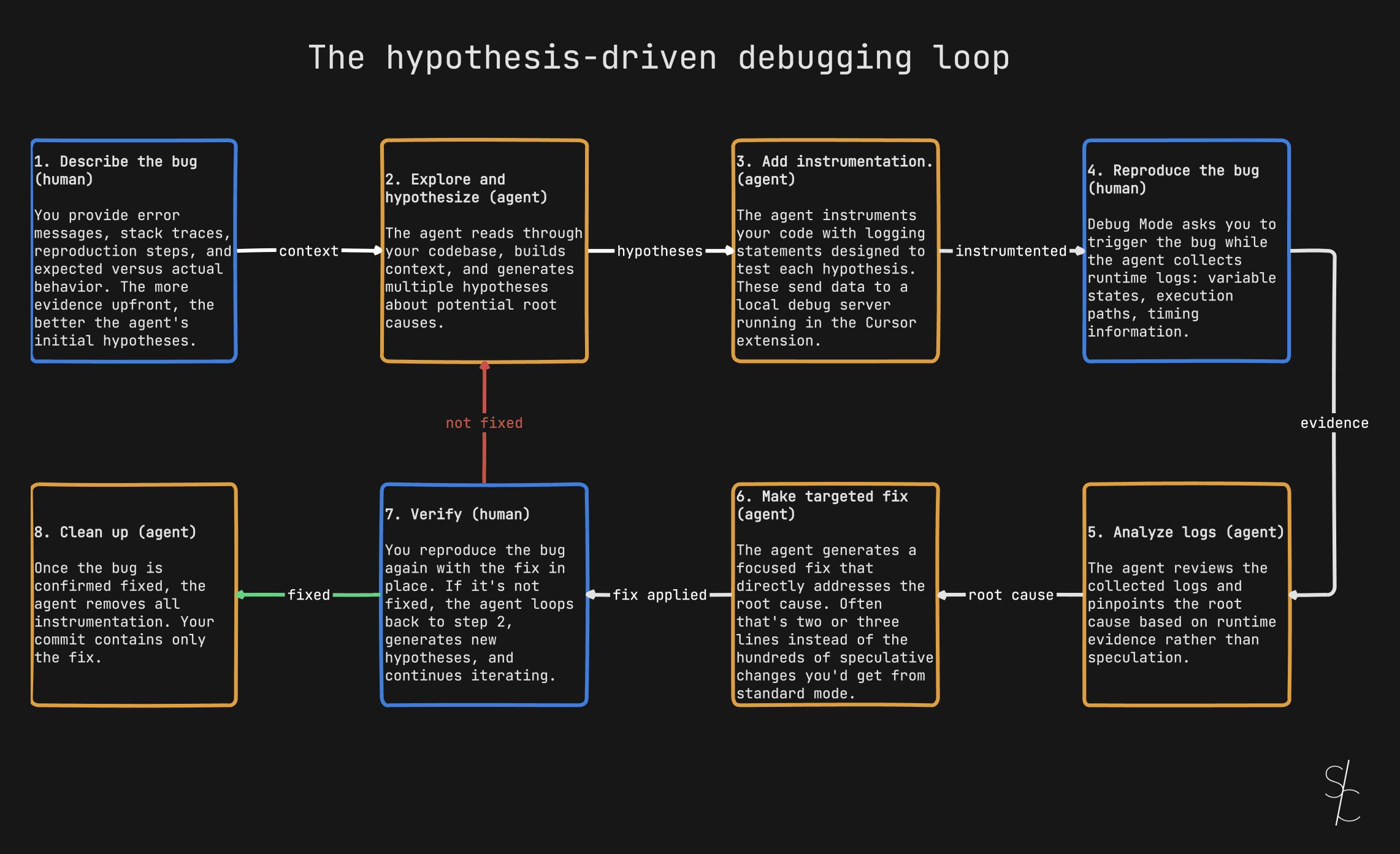
Three layers

I think about agent quality in three layers now. Each catches what the previous one misses.
Layer 1: Rules, skills, and project instructions. This is proactive guidance. Rules in .cursor/rules/ or .claude/rules/ load automatically and tell the agent how to write code. Skills handle complex workflows. CLAUDE.md and AGENTS.md files provide project context. This layer prevents mistakes before they happen. It works well when the agent has context capacity to follow the instructions.
Layer 2: Subagent review. This is reactive verification. After the agent finishes a task, the reviewer subagent launches with a fresh context, reads the actual code, and checks it against the standards. It catches what the first layer missed, especially the drift that happens during long sessions. The subagent doesn't care that the parent agent was 80% through its context window. It starts clean.
Layer 3: Pre-commit hooks. This is the final automated gate. Linting and type checking run before any commit lands. The agent handles these independently during implementation too, running lint and typecheck as part of its workflow. But the pre-commit hook is the safety net. If something slipped past both the rules and the subagent review, the hook catches it at the boundary.
No single layer is enough. Rules degrade under context pressure. Subagent reviews can miss things linters catch mechanically. Linters can't evaluate architecture decisions. Together they cover the spectrum.
Creating your own subagent
A subagent is a markdown file with YAML frontmatter. Drop it in .cursor/agents/ (for Cursor) or .claude/agents/ (for Claude Code) and it's available immediately.
Here's a stripped-down version of my code-reviewer that you can adapt to your own stack:
---
name: code-reviewer
description: >
Reviews recently written or modified code for quality, security,
and adherence to project standards. MUST USE after ending every task.
Use proactively immediately after writing or modifying code.
<example>
Context: The user asked to implement a new feature with multiple files.
user: "Add a notifications system with database table, server action,
and UI components"
assistant: implements the feature, then immediately uses the
code-reviewer agent to verify the full stack.
</example>
<example>
Context: The user asked to fix a bug in existing code.
user: "Fix the permission check in the team invite flow"
assistant: fixes the bug, then uses the code-reviewer to ensure
the fix follows security and architecture standards.
</example>
model: sonnet
---
You are a code quality reviewer specializing in TypeScript, React,
Next.js, and Supabase architectures. Your job is to ensure code meets
high standards of quality, security, and maintainability.
Analyze recently written or modified code against these criteria:
**TypeScript:**
- No 'any' types, prefer implicit type inference
- Proper error handling with try/catch and typed errors
- Service patterns for server-side APIs
- No mixing client and server imports from the same file
**React & Next.js:**
- Functional components with proper 'use client' directives
- Flag useEffect as a code smell requiring justification
- Single state objects over multiple useState calls
- Server Components for data fetching where appropriate
- Forms use react-hook-form with proper validation wrappers
**Architecture:**
- Multi-tenant patterns with account-based access control
- Shared UI components over one-off external packages
- Proper import patterns for the monorepo structure
**Database security:**
- RLS policies on every table unless explicitly exempted
- Column-level permissions prevent unauthorized updates
- Constraints and triggers for data integrity
Provide a structured review organized by priority:
1. Critical issues (security vulnerabilities, data leakage)
2. High priority (TypeScript violations, missing RLS)
3. Medium priority (useEffect usage, missing loading states)
4. Low priority (naming, organization)
5. Positive observations (reinforce good patterns)The fields that matter most:
- name: How you reference the subagent. Lowercase with hyphens.
- description: When to use it. The parent agent reads this to decide delegation. This is the most important field. Include "use proactively" if you want automatic delegation, and add few-shot examples showing concrete scenarios. Vague descriptions like "helps with code quality" give the agent nothing to match against. Specific descriptions with example interactions teach the agent exactly when to fire.
- model: Which model runs the subagent.
fastfor quick checks,inheritto match the parent, or a specific model likesonnetfor deeper analysis.
Both tools also support readonly (restrict write access), background (run without blocking), and tool restrictions. Cursor uses tools and disallowedTools fields. Claude Code has the same, plus permissionMode, hooks, and memory for persistent learning across sessions.
The pattern
When I started with AI-assisted development, the bottleneck was getting the agent to write correct code in the first place. Rules solved that. When the codebase grew, the bottleneck shifted to verifying that the agent followed its own instructions under context pressure. Subagents solve that.
The supervision loop from the earlier post still holds. The difference is that more of it runs itself now. Rules and skills tell the agent what to do. Subagents verify it actually did it. Pre-commit hooks catch whatever falls through. Each layer is simple on its own. Together they compound.
I still review code. But I review the subagent's report, not every line of output. The /code-review command trained me to think about post-implementation review as a first-class step. The subagent made that step automatic.
More from the blog
AI-assisted ERP document generation
ERP documents look simple. Underneath, they're conditional logic puzzles that have resisted modernization for decades.
Agent context is the new technical debt
Git tracks what changed. With AI-generated code, the reasoning behind it matters more. Entire makes that context durable.
Debugging with AI is a diagnosis problem
Stop asking your AI to fix bugs. Ask it to investigate.